Chaining multiple HTTP API’s via Apache NiFi
May it be streamlining a set of defined steps or any finite automata, automation has become a routine in many organisations. I believe there are many tools and frameworks which help us achieve this. Apache NiFi is one such tool for any organisation which requires to onboard data and transform the same via a defined workflow.
Apache NiFi has been around the industry from long and to quote Wikipedia on its origin, it has a unique introduction:
Leveraging the concept of Extract, transform, load, it is based on the “NiagaraFiles” software previously developed by the US National Security Agency (NSA), which is also the source of a part of its present name — NiFi. It was open-sourced as a part of NSA’s technology transfer program in 2014.
There are various connectors or so-called Processors in Apache NiFi which can be leveraged to orchestrate a set of instruction. In this blog, I will provide inputs over how to automate a data pull strategy via chaining a set of API in Apache NiFI.
For this blog please note the tools used:
- Apache NiFi Version: 1.11.1
- The OS under consideration: MacOS
What are we going to build?

The above diagram shows too many processors, but trust me, it’s basically these below steps:
- Hit a POST API to get a Token using a Login and Password
- Consume the token from step 1 and hit another POST API to get the Report URL
- Consume the Report URL from step 2 and use the same token from step 1 to get the actual report downloaded via a GET API
- Upload the report to AWS S3
How are going to build this?
So we need Apache’s InvokeHttp to do the job for hitting the API via POST and GET request.

Apache NiFi’s InvokeHttp Processor and it’s current usage
Apache NiFi has a couple of processors to get API data from any given API provider. For instance, they already had GetHTTP, PostHTTP processors and then later introduced InvokeHttp which has support for Expression Language, support for incoming flowfile. The InvokeHttp processor helps us to trigger a Post API and consume its response. This, however, isn’t straightforward and would require us to configure it right to ensure the post body or headers are passed to the same via a set of supporting processors.
In order to being, let’s start with step by step:
- Hit a POST API to get a Token using a Login and Password
An InvokeHTTP for POST requires a Body/Headers to be passed via a flowfile and we can generate one using the following:
- GenerateFlowFile

This processor generates the required FlowFile (which is to store data for HTTP). The configurations here depict that its size is 1byte to start with and 1 batch size. Do note that the Scheduling tab has been changed to Run Schedule of 60 mins. Unless this, it would keep generating flowfile randomly.
- UpdateAttribute
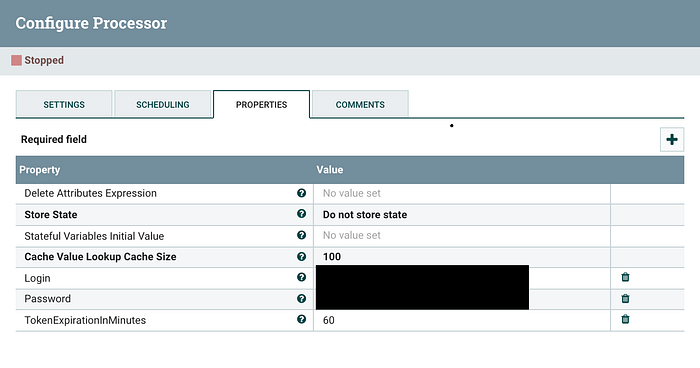
Now the update attribute is used to add the attributes to the FlowFile. A flowfile has attribute and content. Attributes can be used for HTTP Headers and Contents as HTTP Body. The example here shows how we can add a new key-value pair and then in the next step make it part of flowfile’s content
- AttributeToJSON
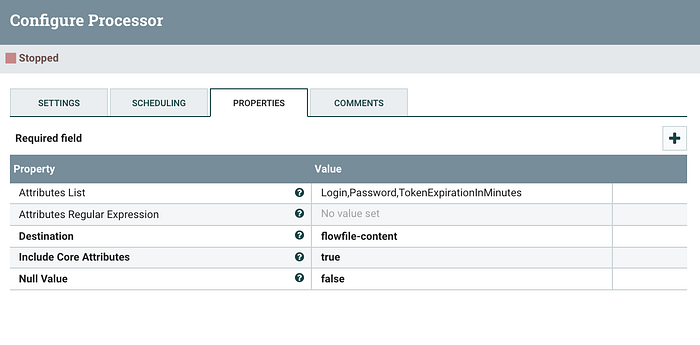
As the previous processor ends up adding it to FlowFile, we now use this processor firstly to CHOOSE the right set (i.e. via AttributesList) of attributes and make it part of the Post body via flowfile-content. Now, the Login, Password and so on can come into flowfile content.
- InvokeHttp


The previous flowfile contents are default sent as a Body to the HTTP and thus it would then result in a trigger of an API. The above-mentioned API is from an example of one of our data provider TheTradeDesk
2. Consume the token from step 1 and hit another POST API to get the Report URL
Once I have the API triggered, this API would send the token as part of the response body. So we need to use consume the token as the next step:
- EvaluateJSONPath

In order to consume the previous API’s output which is JSON Body, we need to use EvaluateJSONPath processor. The output was as follows with:
{ “Token”: “<actual_token>” }
So we ended up with $.Token
- UpdateAttribute

Once we have the Token evaluated from the response body of the HTTP API, we then need to make it part of the FlowFile to feed it into the next API which requires us to download the file.
- AttributeToJSON
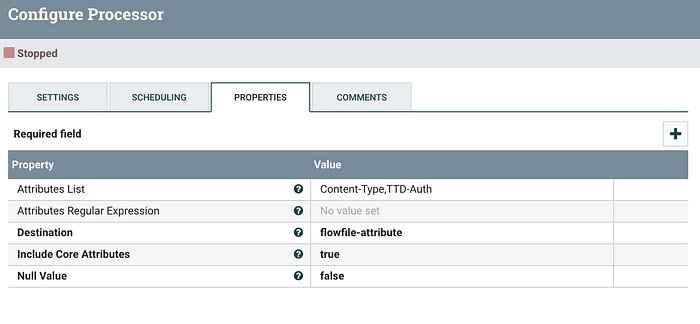
To ensure the above token can be sent as an HTTP Header in InvokeHTTP, we should pass the above attributes as an HTTP header to the next post API. Thus choosing the Destination as flowfile-attribute as expected by InvokeHTTP.
- ReplaceText
Now comes the most important part for this API, we need to pass the JSON Body to the HTTP Post request as:
{
"PartnerIds": [
"61ikbrz"
],
"ReportExecutionStates": [
"Complete"
],
"SortFields": [
{
"FieldId": "ReportStartDateInclusive",
"Ascending": "false"
}
],
"PageStartIndex": 0,
"ReportScheduleNameContains": "Report Name",
"PageSize": 2
}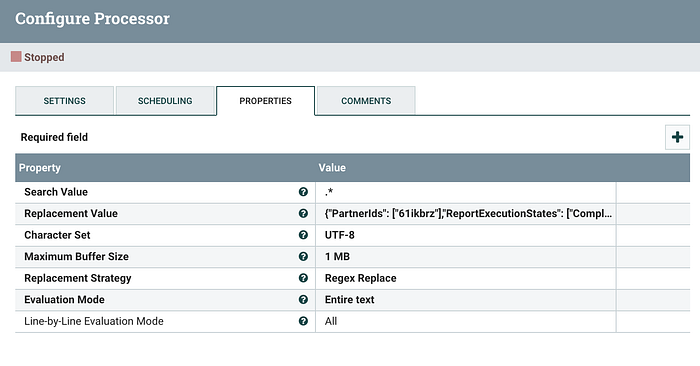
So ensured to search and replace all the data from existing flowfile's content body using, .* and then putting the Replacement Value as the above JSON Post Body. This will ensure to update the corresponding flowfile content which is used as a post request to the InvokeHTTP processor.
- InvokeHTTP


Now do note the above screenshot, we have added the header information gathered from the flowfile’s attribute as TTD-Auth from the previous step of UpdateAttribute. This will ensure the HTTP API’s headers and post body is set as expected.
3. Consume the Report URL from step 2 and use the same token from step 1 to get the actual report downloaded via a GET API
Once the above InvokeHTTP is successful, the mentioned API would return us a response with the file’s Download URL, which is basically an HTTP redirect based download.
- EvaluateJsonPath

If you notice carefully, the following processor helps to extract the download URL and add’s it to the flowfile-attribute which is the header of the HTTP request. The response is a nested JSON which would have the download URL for the file.
- InvokeHTTP
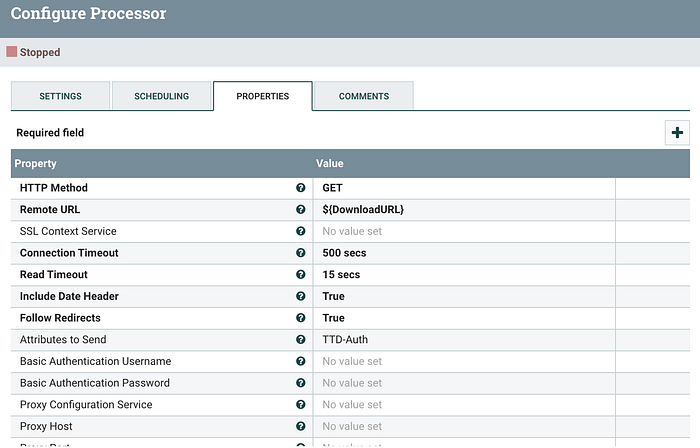
We then use the ${DownloadURL} key from the previous step and then pass it to be downloaded in the remote URL property.
4. Upload the report to AWS S3
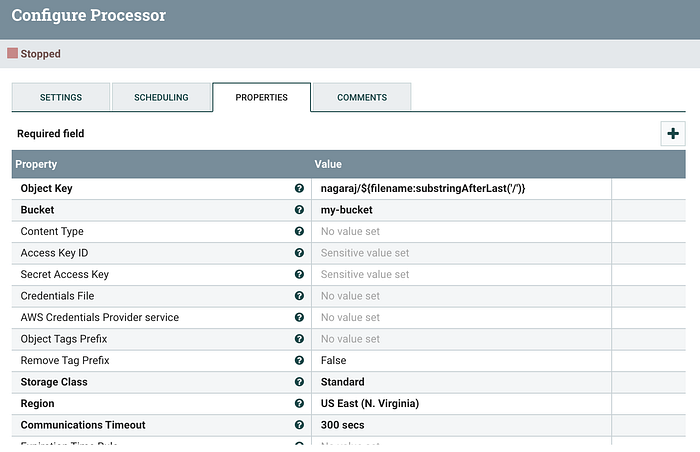
Lastly being downloaded to S3 of our choice.
Concluding
It is definitely a rollercoaster ride to build something so simple in Apache NiFi, but I am pretty sure a tool of its stature is definitely not for only such tasks and can be used for many other requirements and heavy lifting like S3 data transfer with huge volumes (running in cluster mode), or real-time data ingestion to Kafka and so on. I just wanted to provide an update on how to perform this in Apache NiFi, as for sure I struggled to initially get this automated.
